"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In diesem Notebook werden wir beginnen, im allgemeinen Machine Learning Process die nächsten Punkte zu erklären. Insbesondere wollen wir anfangen zu verstehen, wie (Machine Learning) Modelle aussehen und wie sie funktionieren."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Der ML-Process"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"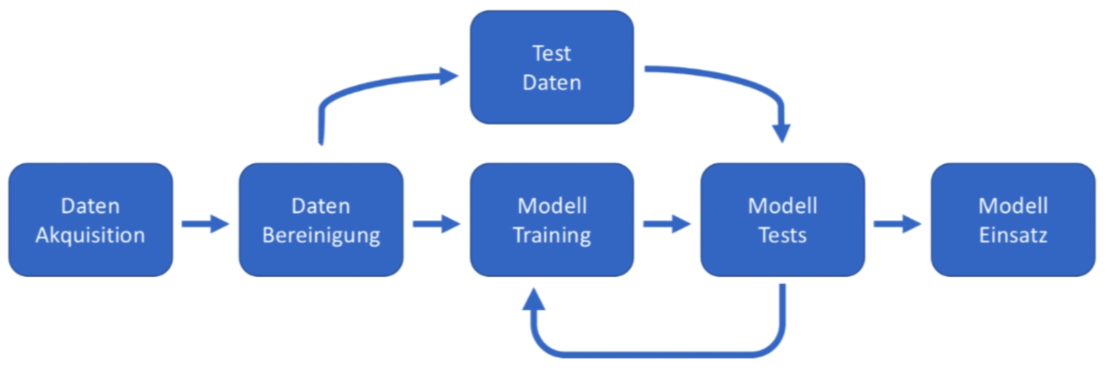\n",
"\n",
"(von AI Inside Seminar KI Mag. Otto Reichel)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Was haben wir **bisher** gemacht:\n",
"* Daten Akquisition:\n",
" * Wie sammle ich meine Daten?\n",
" * Umfragen, Logging, Scraping\n",
"* Daten Bereinigung:\n",
" * Normalisieren\n",
" * Fehlende Werte behandeln"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Nun sehen wir uns die **Grundlagen** zu den Punkten\n",
"* Model Training\n",
"* Train/Test Daten\n",
"* Model Tests\n",
"* Model Einsatz"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Wichtig**: Machine Learning Process ist, wie im Bild gezeigt, ein sehr interaktiver Vorgang.\n",
"\n",
"Machine Learning ist also nicht immer zwingend genau ein konkreter Vorgang: Es spielen immer viele Dinge zusammen."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Unterschied zur normalen Informatik:\n",
"* Wir lernen von Daten; **NUR** von Daten!\n",
"\n",
"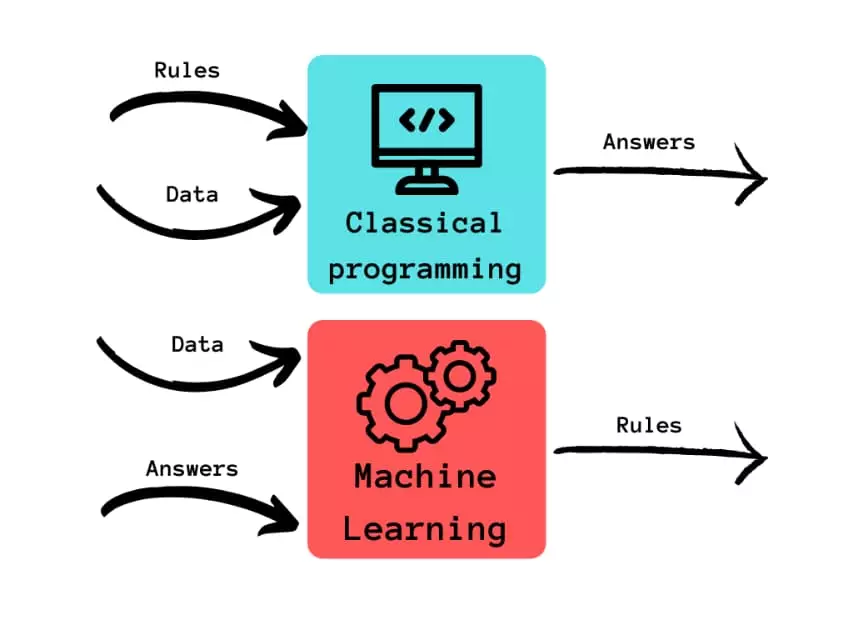\n",
"\n",
"(von https://www.linkedin.com/pulse/machine-learning-vs-classical-ai-muhammad-imran-arshad-6anlf/)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wir unterscheiden zwischen **Supervised** und **Unsupervised** Methoden!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Supervised Machine Learning vs. Unsupervised ML Learning"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Supervised Machine Learning"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* In den Trainings-/Testdaten ist die vorherzusagende Große enthalten. An Hand der Eingangsdaten (Features) $X = (x_1, x_2, \\ldots, x_n)$ soll die gekennzeichnete Große $y$ (Label) vorhergesagt werden. **Wichtig**: Das Label kann sowohl eine Zahl sein, als auch eine Klasse!\n",
"* Zum Beispiel konnte der Preis (=Label) eines Gebrauchtwagens an Hand der Features Baujahr, PS, Marke, km-Stand, Antriebsart vorhergesagt werden.\n",
"* Der lernende Algorithmus erhalt beim Training Datensätze, die sowohl die Features (Eingangsdaten) als auch den korrekten Output (Label) enthalten\n",
"und lernt dazu, indem er den aktuellen Output des Modells mit dem korrekten Output vergleicht und versucht, den Fehler zu minimieren. In dieser Phase verbessert er das Modell iterativ.\n",
"* Eines der Haupteinsatzgebiete von Supervised Learning ist die Vorhersage zukunftiger Daten aus historischen Daten.\n",
"\n",
"(aus AI Inside, Seminar KI; Mag. Otto Reichel)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"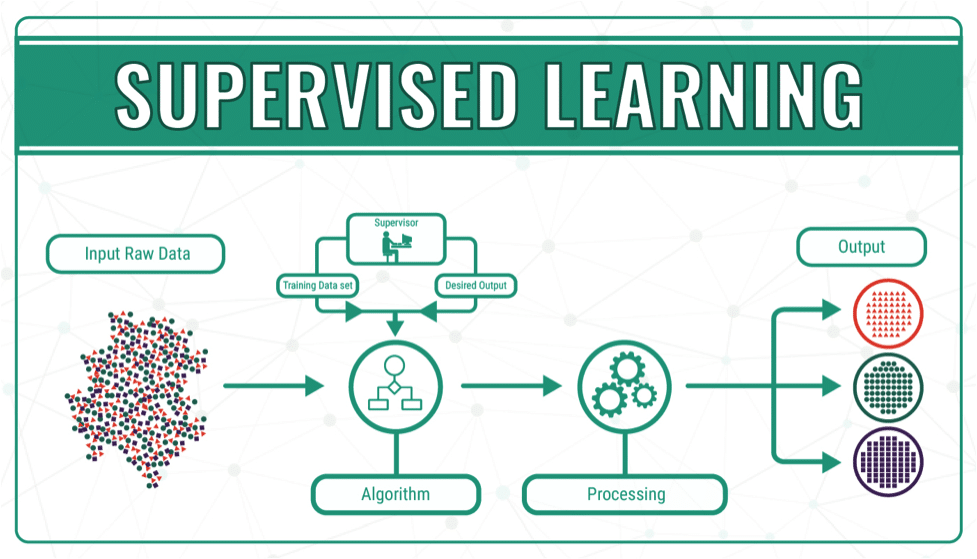\n",
"\n",
"(von https://www.vproexpert.com/what-is-the-difference-between-supervised-and-unsupervised-machine-learning/)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Unsupervised ML"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* In den Trainings-/Testdaten ist die vorherzusagende Größe nicht enthalten (Daten sind ohne Label - Unlabeled). An Hand der Eingangsdaten (Features) $X=(x_1, x_2, \\ldots, x_n)$ sind Gruppen zu finden, die zusammengehörige Daten repräsentieren\n",
"* Dem System wird in der Trainingsphase (kein echtes \"Training\", aber es wird das Model an die Daten angepasst) kein richtiges Ergebnis geliefert\n",
"* Das Hauptziel ist die Analyse der Daten und das Auffinden von zugrundeliegenden Mustern.\n",
"\n",
"(aus AI Inside, Seminar KI; Mag. Otto Reichel)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"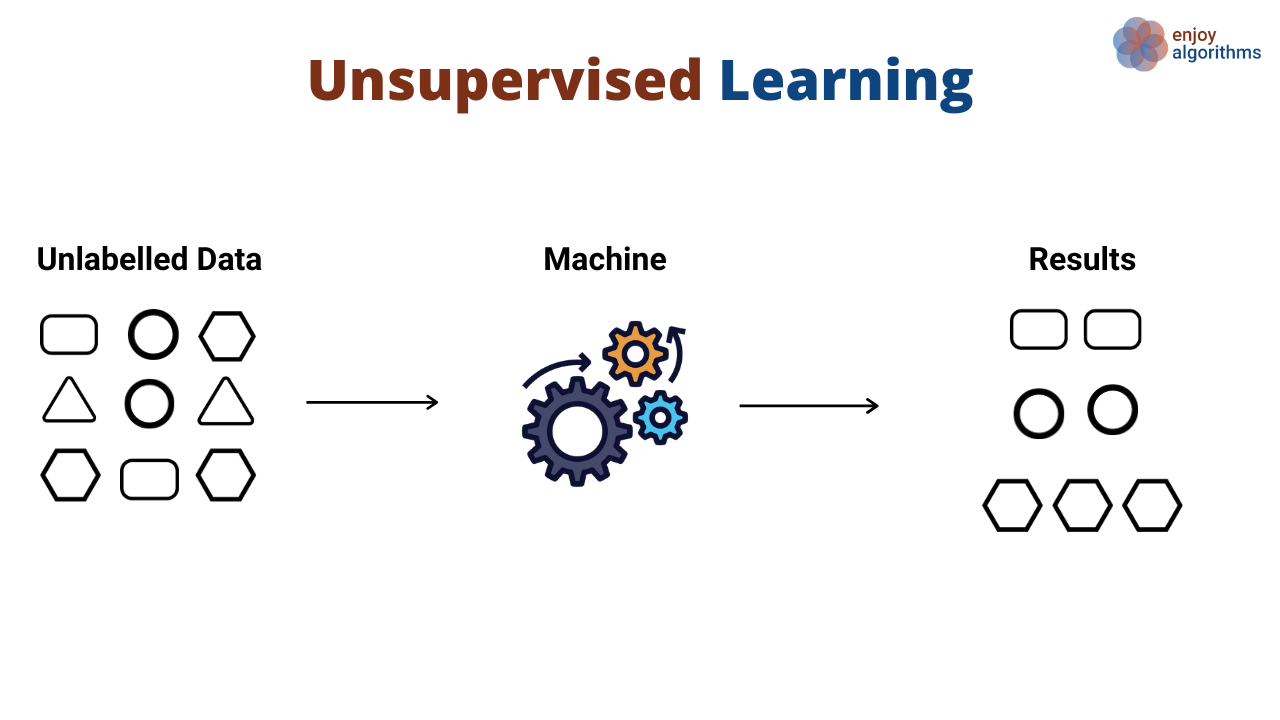\n",
"\n",
"(von https://www.linkedin.com/pulse/unveiling-top-5-unsupervised-machine-learning-algorithms-yadav-0yikc/)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In beiden Fällen stellt $X$ nun den Feature Vektor dar. Unser Dataset besteht dann normalerweise aus $m$ solchen Vektoren der Größe $n$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Beispiele:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Beispiel1:\n",
"Einem Machine Learning Modell werden immer 2 Zahlen gegeben. Dabei ist die erste Zahl das Feature und die 2. Zahl das Label.\n",
"Das Modell soll lernen, für neue Daten, die 2. Zahl zu erraten. Die Daten sehen dabei folgendermaßen aus:\n",
"$$\\{(1,1), (4, 16), (-2, 4), \\ldots, (9, 81)\\}.$$\n",
"\n",
"Welchen Zusammenhang soll das Modell hier lernen? Was soll das Modell für den Input $10$ vorhersagen?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Beispiel2:\n",
"Einem Machine Learning Modell wird immer eine Integer Zahl und ein Bit ($0$ oder $1$) gegeben. Das Model soll lernen, welche Zahlen das Bit $1$ und welche Zahlen das Bit $0$ bekommen.\n",
"Die Daten sehen so aus:\n",
"$$\\{(1,0), (4,1), (8, 1), (9,0), (10,1), \\ldots, (-4, 1)\\}.$$\n",
"\n",
"Welcher Zusammenhang wurde hier gelernt? Welchen Wert soll das Modell für den Input $17$ vorhersagen?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Beispiel3:\n",
"Ein Machine Learning Modell bekommt eine Liste von MP3 Dateien (zBsp eine Playlist auf Spotify) und soll die Lieder gruppieren. Das Modell bekommt keine anderen Infos und soll sich selber \"überlegen\", wie es am besten sortiert. Ein (für uns Menschen) vernünftiges Ergebnis wäre zum Beispiel eine Gruppierung nach Genre, Heavy Metal vs. Pop vs. Rap vs. Electronic zum Beispiel. Nun kann ein neues Item (ein neues Lied) auch in den Algorithmus gegeben werden und wir erhalten eine Gruppe für dieses Element. \n",
"\n",
"Was wurde hier ggf. gelernt? Was könnte noch gelernt worden sein? Handelt es sich hier um Supervised oder Unsupervised Learning?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Beispiel4:\n",
"Ein Machine Learning Modell bekommt eine Gallerie auf dem Smartphone voller Fotos. Es erstellt je nach abgebildeten Personen (hauptsächlich über das Gesicht) eigene Ordner welche nur Fotos von diesen Personen beinhalten.\n",
"\n",
"Was wurde hier gelernt? Ist es Supervised oder Unsupervised?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wir werden uns heuer noch mit folgenden **Supervised** Modellen befassen:\n",
"* **Regression und logistische Regression**\n",
"* **kNN (K-Nearest-Neighbor)**\n",
"* **SVM (Support Vector Machine)**\n",
"* **Decision Tree und Random Forests**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wir werden uns heuer noch mit folgenden **Unsupervised** Modellen befassen:\n",
"* **k-means und affinity propagation**\n",
"* **Downprojection**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wir werden uns jetzt am Anfang hauptsächlich mit **Supervised Machine Learning** Modellen beschäftigen."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Supervised Machine Learning"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Die wesentlichen Hauptkategorien im Bereich **Supervised Machine Learning** sind **Regression** und **Klassifikation**."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"(von https://www.simplilearn.com/regression-vs-classification-in-machine-learning-article)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Regression**:\n",
"* Für gegebene Features $X=(x_1, x_2, \\ldots, x_n)$ soll ein reeller Wert $y\\in\\mathbb{R}$ (=Label) vorhergesagt werden\n",
"* **Beispiel:** Aus Features Kilometerstand, Baujahr, Marke, Antriebsart, PS und Hubraum den Verkaufspreis eines Gebrauchtwagens vorhersagen"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Classification**:\n",
"* Für gegebene Features $X=(x_1, x_2, \\ldots, x_n)$ soll eine Klasse (oft binär, zBsp Katze/Hund) $y\\in\\{0,1\\}$ (=Label) vorhergesagt werden\n",
"* **Beispiel:** Aus Features Blutdruck, Blutzucker, Rauchverhalten, BMI hervorsagen, ob eine Person Schlaganfall (Stroke) gefährdet ist"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Welche Art von Supervised Learning waren die beiden vorigen Beispiele?\n",
"\n",
"Müssen die Klassen immer $0,1$ sein bzw. für $n$ Klassen dann $0,1,\\ldots, n-1$?\n",
"\n",
"Inwiefern bringt uns hier ein **OrdinalEncoder** etwas? Was würde ein **OneHotEncoder** für einen Output liefern?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Bei jedem (Supervised) Modell gibt es immer 2 Phasen, von denen unterschieden werden muss:\n",
"* **Training** (Lernen)\n",
"* **Prediction** (Vorhersage), auch Inferenz genannt\n",
"\n",
"\n",
"Allgemein läuft der (ungefähre) Vorgang wie folgt ab:\n",
"* Auswahl einer Model-Klasse, abhängig von den gegebenen Daten bzw. des gewünschten Tasks\n",
"* Training (=Lernen) des Models mit den gegebenen Daten\n",
"* Testen, ob das gelernte Model \"gut\" ist\n",
"* Verwenden vom Model"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Lernen (Training) und Vorhersage (Prediction) von Modellen"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Lernen (Training)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wir betrachten nun den Lernvorgang von einem Modell.\n",
"\n",
"**Wichtig:** Dieser Prozess ist, je nach verwendetem Modell Typ, sehr unterschiedlich. Je nach Typ wird beim Lernen versucht ein Fehler zu minimieren (Loss basiert) oder es nach anderen Kriterien optimiert zBsp.: Entropie bei Entscheidungsbäumen oder Decision Boundaries bei K-Nearest-Neighbor Modellen. \n",
"\n",
"Wir werden die verschiedenen Lernprozesse dann für die einzelnen Modelle genauer durchmachen.\n",
"\n",
"Als Beispiel betrachten wir jetzt das Lernen anhand von einem Regressionsmodell, welches versucht, eine Kurve (=Funktion, zBsp Polynom) in die gegebenen Daten (=Punkte) hinein zu legen."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Man kann sich das Lernen in dem Fall von Regression auch iterativ vorstellen:\n",
"1. Punkte (Daten) sind gegeben.\n",
"1. Fixiere die Modell Klasse (Zum Beispiel Lineare Regression $y=kx+d$)\n",
"1. Wähle zufälliges $k,d$ und bewerte das Ergebnis\n",
"1. Ändere $k,d$, sodass Funktion besser in die Daten passt. Bewerte erneut, $\\ldots$ usw. bis Ergebnis zufriedenstellend.\n",
"\n",
"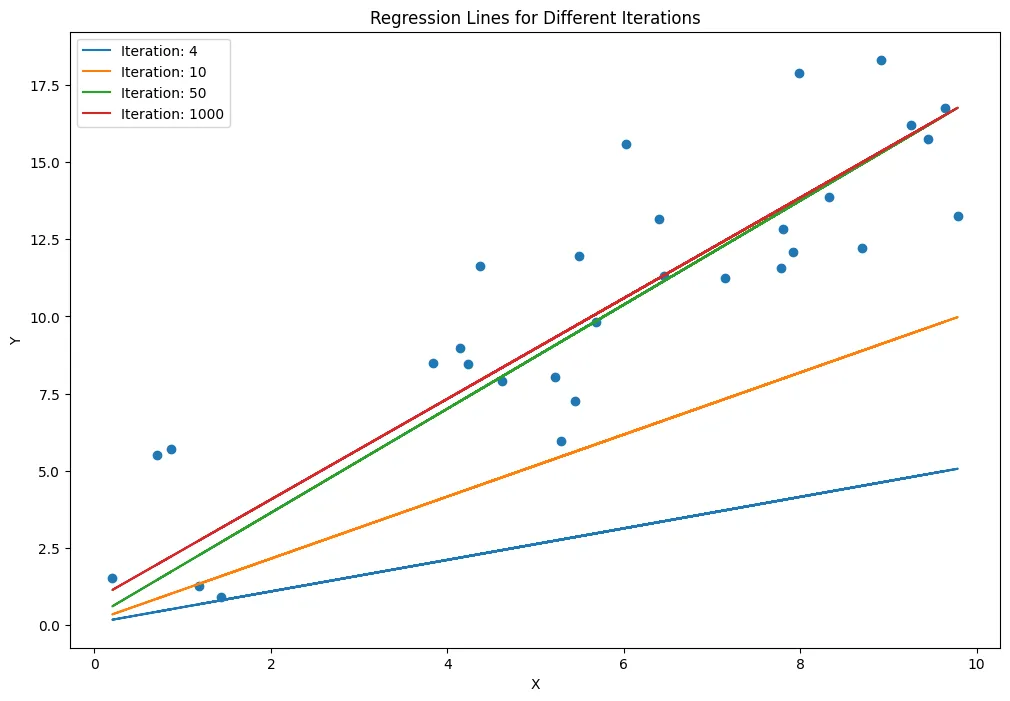\n",
"\n",
"(von https://sandundayananda.medium.com/linear-regression-4c327a5d5ba7)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Nettes Tool zum Probieren: https://visualize-it.github.io/polynomial_regression/simulation.html\n",
"\n",
"Hier sieht man auch, wie sehr die Datenqualität eine Rolle spielt (betrachte sehr wenige Punkte, oder alle Punkte fast gleich)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prediction von Modellen"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Nachdem ein Modell fertig trainiert bzw. an den Daten angepasst wurde, kann es für die Prediction verwendet werden.\n",
"\n",
"Bei unserer linearen Regression würde das folgendes bedeuten:\n",
"* Wir fixieren nun $k$ und $d$ und ändern diese nicht mehr\n",
"* Der vorhergesagte Wert für einen neuen Datenpunkt $x_m\\in\\mathbb{R}$ wird dann berechnet, indem man einfach den Funktionswert für diesen Punkt berechnet\n",
"* $y_m = k \\cdot x_m + d$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Beurteilung des gelernten Models"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Sobald wir ein Modell fertig trainiert haben, ist es eine legitim zu Fragen **\"Wie gut das Modell nun eigentlich ist\"**."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Dieser Punkt wird **Modell Evaluierung** genannt. \n",
"\n",
"Welche Funktionen funktionieren [hier](https://visualize-it.github.io/polynomial_regression/simulation.html) gut und welche schlecht für verschiedene Datenpunkte? "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Obwohl das hier intuitiv recht gut funktioniert, kann man für größere Modelle nicht mehr rein intuitiv sagen, ob das Modell nun gut funktioniert, oder auch nicht.\n",
"\n",
"Dementsprechend gibt es eigene **Metriken**, welche trainierte Modelle evaluieren. Dies werden wir uns im nächsten Notebook ansehen."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Aufgabe"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Überlege (oder verwende das Internet und recherchiere), welche Methode (Supervised/Unsupervised) die bekannten KI's im Alltag (Copilot, Bilderkennung, ChatGPT, Stable Diffusion, Self-Driving Cars, etc.) verwenden\n",
"* Was sind die Daten? Was sind ggf. die Labels? Gibt es überhaupt Labels?\n",
"* Gibt es Tasks in deinem Alltag (oder zum Beispiel bei der Diplomarbeit), wo du glaubst, man könnte da vielleicht KI einsetzen? Gibt es dafür (labeled) Data?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "dsai",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.20"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
 \n",
"
\n",
"