"
]
},
{
"cell_type": "markdown",
"id": "65f25f8a",
"metadata": {},
"source": [
"In diesem Notebook wollen wir nun besprechen, wie ein Neuronales Netzwerk lernt.\n",
"\n",
"Dazu können wir uns zuerst einmal fragen, was eigentlich **Lernen** bedeutet?"
]
},
{
"cell_type": "markdown",
"id": "66bf621f",
"metadata": {},
"source": [
"> A computer program is said to **learn** from **experience E**\n",
"with respect to some class of **tasks T** and\n",
"performance **measure P**, if its performance at tasks in T,\n",
"as measured by P, improves with experience E.\n",
"\n",
"(Mitchell 1997)"
]
},
{
"cell_type": "markdown",
"id": "f0de04ed",
"metadata": {},
"source": [
"Was bedeutet das in unserem Fall?\n",
"\n",
"* Wir sagen, dass unser Modell lernt, falls es bei einer gegebenen Aufgabe *besser wird*:\n",
" * Was ist die Aufgabe bei uns?\n",
" * Wie messen wir, ob es besser geworden ist?"
]
},
{
"cell_type": "markdown",
"id": "9b8f0f43",
"metadata": {},
"source": [
"## Die Problemstellung"
]
},
{
"cell_type": "markdown",
"id": "078d9fcf",
"metadata": {},
"source": [
"### Die Ausgangslage"
]
},
{
"cell_type": "markdown",
"id": "886dca89",
"metadata": {},
"source": [
"Wir betrachten jetzt nochmal im Detail unsere Problemstellung.\n",
"\n",
"Wir haben Daten für ein Supervised Machine Learning Setting, sprich wir haben eine Menge $\\mathcal Z$, welche aus den Paaren $(X_i, y_i)$ besteht, wobei $X_i$ der Feature Vektor für den $i$-ten Datenpunkt und $y_i$ das dazugehörige $i$-te Label (Regression oder Klassifikation) ist.\n",
"\n",
"Ziel ist es, eine Funtion $f$ zu finden, welche uns diesen Zusammenhang abbildet."
]
},
{
"cell_type": "markdown",
"id": "d89c746a",
"metadata": {},
"source": [
"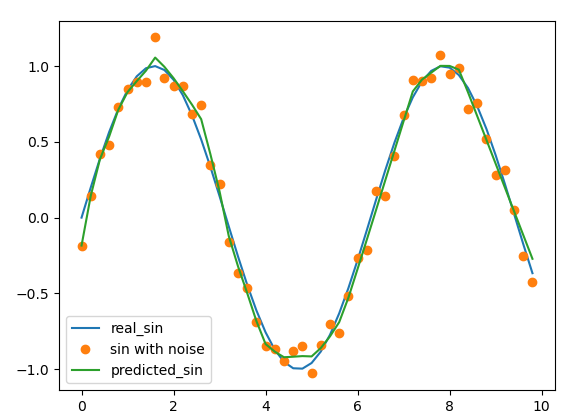\n",
"\n",
"(von https://stackoverflow.com/questions/13897316/approximating-the-sine-function-with-a-neural-network)"
]
},
{
"cell_type": "markdown",
"id": "198251b5",
"metadata": {},
"source": [
"Was wird in unserem Fall in Zukunft die Funktion $f$ sein?"
]
},
{
"cell_type": "markdown",
"id": "42e15ecc",
"metadata": {},
"source": [
"### Der Task eines Neuronalen Netzwerkes"
]
},
{
"cell_type": "markdown",
"id": "996f0170",
"metadata": {},
"source": [
"Was ist nun die Aufgabe von unserem Neuronalen Netz?\n",
"\n",
"Wir wollen die gegebenen Datenpaare gut mit unserem neuronalen Netz abbilden können. Sprich unser Neuronales Netzwerk soll überall ähnliche (bzw. die gleichen Werte) ausspucken."
]
},
{
"cell_type": "markdown",
"id": "1e300848",
"metadata": {},
"source": [
"Wie können wir das überprüfen?\n",
"\n",
"Händisch können wir natürlich die Ergebnisse mit den originalen Ergebnisse gut vergleichen und die Qualität beurteilen. Dies ist aber mühsam, somit stellt sich uns die Frage, wie wir sonst vorgehen können? Für eindimensionale Daten können wir auch eine Kurve (so wie oben) plotten, auch das ist einfach. Dies ist aber auch in der Praxis meistens nicht der Fall."
]
},
{
"cell_type": "markdown",
"id": "dc1ba5a1",
"metadata": {},
"source": [
"Um den Fehler quantifizieren zu können, widmen wir uns jetzt den sogenannten **Loss**-Funktionen. Sie sind uns schon von der linearen (bzw. logistischen) Regression bekannt und geben uns den Fehler, den das Modell macht."
]
},
{
"cell_type": "markdown",
"id": "e9353e7f",
"metadata": {},
"source": [
"### Die Loss Funktion"
]
},
{
"cell_type": "markdown",
"id": "fc0b1508",
"metadata": {},
"source": [
"Die Loss Funktion gibt uns den Fehler zurück, den das Netzwerk aktuell für einen Input $X_i$ im Vergleich zum Ziel Output $y_i$, macht.\n",
"\n",
"Wir schreiben von nun an für den Loss:\n",
"$$L(\\hat{y}_i, y_i)=L(\\hat f(X_i), y_i),$$\n",
"\n",
"wobei sämtliche Größen mit $\\mathbf{\\hat{}}$-Symbol immer als die von uns approximierten Größen (Predictions) bezeichnet werden."
]
},
{
"cell_type": "markdown",
"id": "b9c9cdf7",
"metadata": {},
"source": [
"Kommen wir nun zu den gängigsten Loss-Funktionen. Wir starten mit den Loss-Funktionen für die **Regression**. Diese sind die gleichen Loss-Funktionen wie für die lineare (logistische) Regression und werden hier kurz aufgezählt."
]
},
{
"cell_type": "markdown",
"id": "8c0cffd0",
"metadata": {},
"source": [
"#### Gängige Loss-Funktionen für Regression"
]
},
{
"cell_type": "markdown",
"id": "cf94e0b3",
"metadata": {},
"source": [
"**MSE:** Mean-Squared Error: $$L_{\\textrm{MSE}}(\\hat{y}, y)=\\frac{1}{n}\\sum_{i=1}^{n}(\\hat{y}_i - y_i)^2,$$\n",
"\n",
"mit $n$ als Anzahl der Datenpunkte."
]
},
{
"cell_type": "markdown",
"id": "82735f2f",
"metadata": {},
"source": [
"**MAE:** Mean Absolute Error: $$L_{\\mathrm{MAE}}(\\hat{y}, y)=\\frac{1}{n}\\sum_{i=1}^{n}\\lvert \\hat{y}_i - y_i\\rvert.$$"
]
},
{
"cell_type": "markdown",
"id": "cecb982a",
"metadata": {},
"source": [
"**Hinweis:** Nachdem wir hier die Regressionsloss-Funktionen betrachten, nehmen wir an, dass es jeweils nur ein Output Neuron gibt. Ansonsten müssten wir die Loss-Funktionen leicht adaptieren hier."
]
},
{
"cell_type": "markdown",
"id": "b893a8d7",
"metadata": {},
"source": [
"#### Gängige Loss-Funktionen für Klassifikation"
]
},
{
"cell_type": "markdown",
"id": "65e773ed",
"metadata": {},
"source": [
"Hier ist der Output immer ein Vektor, welchen wir mit dem Zielvektor vergleichen wollen. Siehe folgendes Beispiel, wo das Label nun offensichtlich die Klasse **Auto** ist. Mit einem OneHot-Encoder erhalten wir das gewünschte Format für die Loss-Funktion, sprich $\\text{Auto}=[1,0,0,0]$."
]
},
{
"cell_type": "markdown",
"id": "9f0b028f",
"metadata": {},
"source": [
"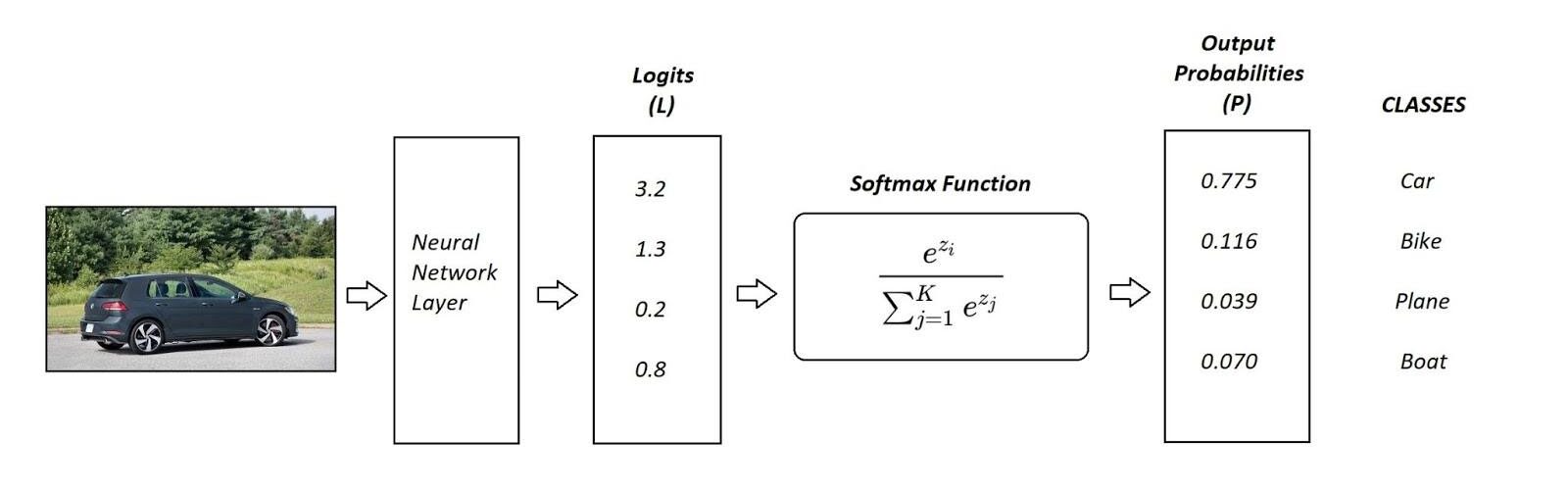\n",
"\n",
"(von https://www.shopdev.co/blog/cross-entropy-in-machine-learning)"
]
},
{
"cell_type": "markdown",
"id": "c0867e68",
"metadata": {},
"source": [
"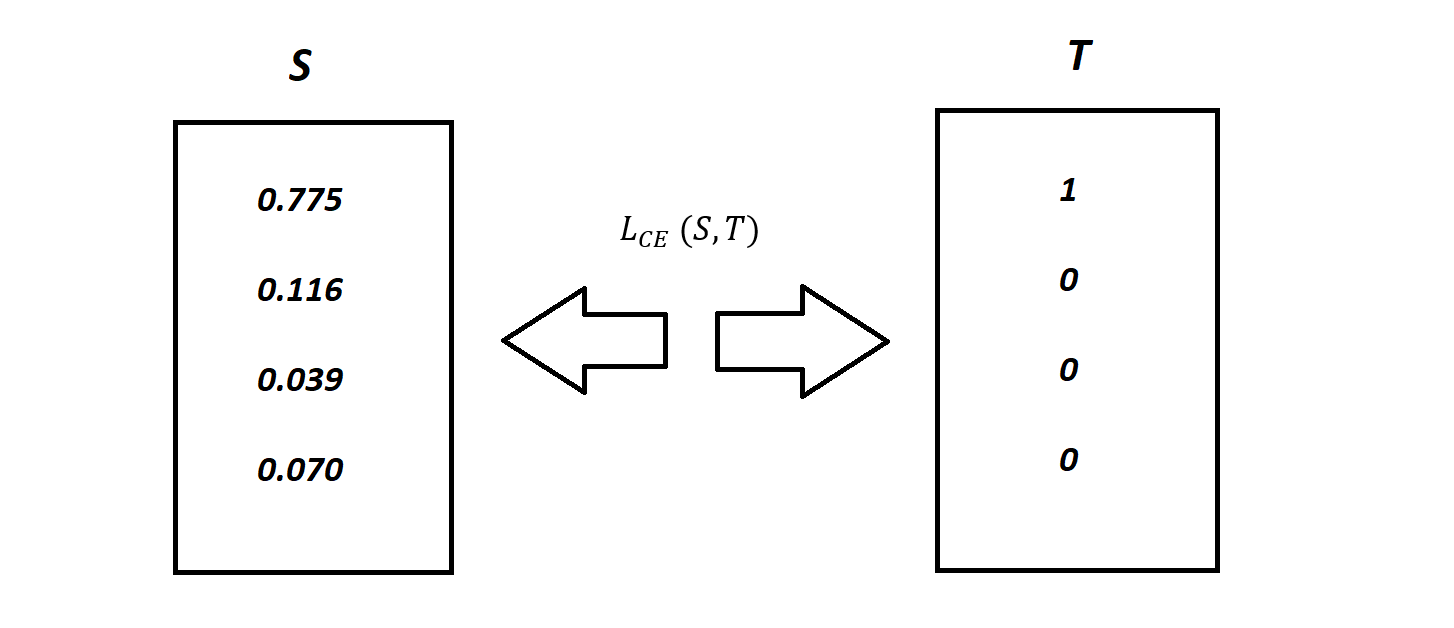\n",
"\n",
"(von https://www.shopdev.co/blog/cross-entropy-in-machine-learning)"
]
},
{
"cell_type": "markdown",
"id": "b612f965",
"metadata": {},
"source": [
"**Categorical Cross-Entropy Loss**: Berchnet, wie sehr sich die Verteilungen $y$ und $\\hat{y}$ ähnlich sind. Er ist folgendermaßen definiert:\n",
"$$L_{\\mathrm{CE}}(\\hat{y}, y)=-\\frac{1}{n}\\sum_{i=1}^{n}\\sum_{k=1}^{K}y_{ik}\\log(\\hat{y}_{ik}),$$\n",
"\n",
"wobei $K$ die Anzahl der Klassen ist, also im obigen Beispiel zum Beispiel 4 und $n$ wieder die Anzahl der Datenpunkte."
]
},
{
"cell_type": "markdown",
"id": "395d0adf",
"metadata": {},
"source": [
"**Binary Cross-Entropy Loss** Spezialfall für nur 2 Klassen vom Categorical Cross-Entropy Loss ($K=2$). Es gilt automatisch, weil die Summe vom Vektor $1$ ergeben muss (repräsentiert ja die Wahrscheinlichkeiten bzw. Predictions), dass $y_{i2} = 1-y_{i1}$. Somit ergibt sich für den Loss:\n",
"$$L_{\\mathrm{BCE}}(\\hat{y}, y)=-\\frac{1}{n}\\sum_{i=1}^{n}[y_i \\log (\\hat{y}_i)+ (1-y_i)\\log(1-\\hat{y}_i)].$$"
]
},
{
"cell_type": "markdown",
"id": "53b31676",
"metadata": {},
"source": [
"**Wichtig:** Hier ist $y$ die Ziel-Verteilung und $\\hat y$ die Verteilung der Vorhersage (Prediction). "
]
},
{
"cell_type": "markdown",
"id": "068fc731",
"metadata": {},
"source": [
"> **Übung:** Warum sind diese beiden Loss-Funktionen mit einem negativen Vorzeichen behaftet?"
]
},
{
"cell_type": "markdown",
"id": "eb96de62",
"metadata": {},
"source": [
"> **Übung:** Wann ist der Loss 0 für den *Binary Cross-Entropy Loss*? Wann für den *Categorical Cross-Entropy Loss*?"
]
},
{
"cell_type": "markdown",
"id": "9fb3bc69",
"metadata": {},
"source": [
"**>Übung:** Der Logarithmus $\\log(x)$ ist für $x\\leq 0$ nicht definiert. Wieso macht uns das hier keine Probleme? *Tipp:* Softmax."
]
},
{
"cell_type": "markdown",
"id": "fb2e3b5f",
"metadata": {},
"source": [
"### Zusammenfassung vom Task eines Neuronalen Netzwerkes:"
]
},
{
"cell_type": "markdown",
"id": "5f1eeacc",
"metadata": {},
"source": [
"Folgende Punkte fassen nun unsere Ausgangssituation zusammen.\n",
"\n",
"* Wir haben ein Neuronales Netzwerk (beliebig \"komplex\", beliebige Aktivierungsfunktionen etc.). Dieses stellt unsere Funktion $\\hat{f}$ dar\n",
"* Wir haben die Datenpaare mit Features $X_i$ und Label (Wert oder Klasse) $y_i$\n",
"* Wir haben die Daten in Trainings- und Testsplit aufgeteilt (zBsp im Verhältnis: 80/20)\n",
"* Wir haben eine Loss-Funktion $L(\\hat{f}(X_i), \\mathbf y_i)$ definiert\n",
"* Diese Loss Funktion wollen wir auf den Trainingsdaten minimieren."
]
},
{
"cell_type": "markdown",
"id": "6e3a49b7",
"metadata": {},
"source": [
"**Wichtig:** Auch wenn wir den Loss auf den Trainingsdaten minimieren, wollen wir in Summe natürlich dann ein Modell, bei dem der Loss am *Testset* niedrig ist. (Nur so können wir überprüfen, dass wir nicht overfitten.)"
]
},
{
"cell_type": "markdown",
"id": "62d6bab0",
"metadata": {},
"source": [
"**Hinweis:** Wir können im Anschluss dann auch noch Metriken berechnen wie zum Beispiel Accuracy, Confusion Matrix, Anzahl der True-Positive samples, etc. Solche Metriken sind für uns Anwender oft von großem Interesse, da sie meistens dann die Brücke bilden zu den Praxisproblemen (zbsp.: Anzahl der Fehlklassifikationen bei Krebs Früherkennung usw.). Der Loss selber wird jedoch benötigt zum Optimieren (=Minimieren), also das Modell soll optimiert werden, sodass wir einen kleinen Loss (Fehler) haben. Der Grund dafür ist, dass wir unsere Loss-Funktion ableiten müssen. Jene Funktionen, die uns die Metriken liefern sind oft nicht differenzierbar."
]
},
{
"cell_type": "markdown",
"id": "6504c924",
"metadata": {},
"source": [
"**Hinweis:** Wir können uns auch eine eigene Loss-Funktionen basteln, welche auf besondere Wünsche/Anforderungen abgestimmt ist. Man muss dabei aber auf ein paar Dinge acht geben (werden wir uns eventuell zu einem späteren Zeitpunkt ansehen)."
]
},
{
"cell_type": "markdown",
"id": "5b3bf26e",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"id": "47b15bc1",
"metadata": {},
"source": [
"### Finden eines Minimums (der Lossfunktion)"
]
},
{
"cell_type": "markdown",
"id": "43a87dfb",
"metadata": {},
"source": [
"Nun bleibt nur mehr die Frage, wie wir das Minimum einer Funktion finden?"
]
},
{
"cell_type": "markdown",
"id": "899c4878",
"metadata": {},
"source": [
"**Erinnerung:** Wie finden wir das Minimum einer Funktion?"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "cc09ad5e",
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"id": "d840a068",
"metadata": {},
"source": [
"> **Übung:** Wie müssen die Parameter $w_1, w_2 \\in \\mathbb R$ gewählt werden, um ein die Funktion $$L(w_1, w_2)=(4w_1+7w_2-20)^2$$ zu minimieren?"
]
},
{
"cell_type": "markdown",
"id": "0d1031a0",
"metadata": {},
"source": [
"> **Übung:** Wie müssen die Parameter $w_1, w_2, w_3 \\in \\mathbb R$ gewählt werden, um ein die Funktion $$L(w_1, w_2, w_3)=\\max (0, 2w_1+3w_2-4w_3)^2$$ zu minimieren?"
]
},
{
"cell_type": "markdown",
"id": "b1e18b34",
"metadata": {},
"source": [
"> **Übung:** Wie muss der Parameter $w_1 \\in \\mathbb R$ gewählt werden, um ein die Funktion $$L(w_1)=\\lvert w_1 - e^{-w_1} \\rvert$$ zu minimieren?"
]
},
{
"cell_type": "markdown",
"id": "5913e518",
"metadata": {},
"source": [
"**Allgemein gilt natürlich:**\n",
"\n",
"Bei einem Extrempunkt ist die Ableitung $0$. Somit berechnen wir hier einfach die (partielle) Ableitung und wir erhalten alle Kandidaten. Im Anschluss können wir dann leicht prüfen, ob es ein Maximum oder Minimum ist (im 1d mit der 2. Ableitung, ansonsten zum Beispiel auch mit Einsetzen und Vergleichen der Werte)."
]
},
{
"cell_type": "markdown",
"id": "7d31eacf",
"metadata": {},
"source": [
"Aber können wir immer so leicht die Ableitung $0$ setzen?\n",
"\n",
"**Nein**, weil unsere Funktionen (neuronalen Netze) sind sehr kompliziert (und besitzen viele Parameter), weswegen das Berechnen der Nullstelle der Ableitung sich als schwierig/unmöglich gestaltet. Dies ist zum Beispiel beim letzten der drei Beispiele auch schon sehr schwer/unmöglich. "
]
},
{
"cell_type": "markdown",
"id": "f4cb3760",
"metadata": {},
"source": [
"Tatsächlich ist dies in der Praxis oft (bei Neuronalen Netzen quasi immer) der Fall, wie die folgenden beiden Grafiken zeigen. "
]
},
{
"cell_type": "markdown",
"id": "d60cd011",
"metadata": {},
"source": [
"\n",
"\n",
"(von https://www.cs.umd.edu/~tomg/projects/landscapes/)"
]
},
{
"cell_type": "markdown",
"id": "3e956bce",
"metadata": {},
"source": [
"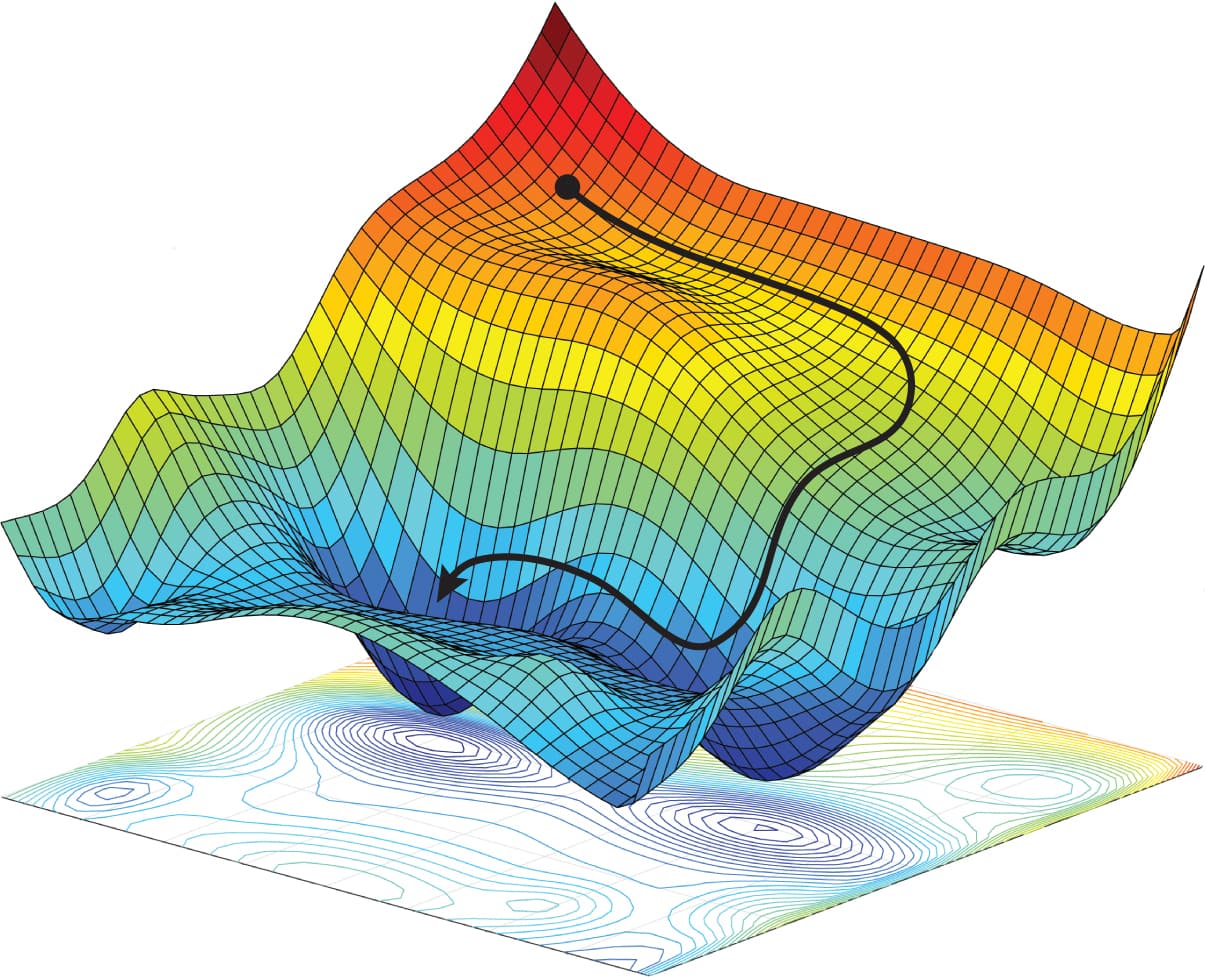\n",
"\n",
"(von https://discuss.pytorch.org/t/looking-for-the-lost-function-generating-the-lost-landscape-shown-in-this-article-on-sceince/130626)"
]
},
{
"cell_type": "markdown",
"id": "2c98dca5",
"metadata": {},
"source": [
"Wie wir oben sehen (diese Art von Bilder nennt man *Loss Landscape*), haben wir bei solchen Funktionen ein riesen Problem, das **globale** Minimum zu finden. Wir haben aber auch schon Probleme überhaupt ein Minimum zu berechnen."
]
},
{
"cell_type": "markdown",
"id": "af53f16d",
"metadata": {},
"source": [
"**Hinweis:** Obige Modelle haben nur 2 Parameter (zum Beispiel hat die Funktion $f(x)=kx+d$ auch nur 2 Parameter ($k, d$)), welche auf den $x$- und $y$-Achsen positioniert sind. Auf der $z$-Achse wird der Loss aufgetragen.\n",
"\n",
"Im Vergleich: Ein Language Model von Meta (llama4) hat etwa 405B Parameter, dass sind 405 Milliarden solcher Parameter, wo wir das gemeinsame Optimimum finden wollen."
]
},
{
"cell_type": "markdown",
"id": "6d65aefa",
"metadata": {},
"source": [
"Was ist, wenn wir das Minimum nicht analytisch berechnen können?"
]
},
{
"cell_type": "markdown",
"id": "ae47f39b",
"metadata": {},
"source": [
"In so einem Fall müssen wir uns einer numerischen/iterativen Methode bedienen, um unser Minimum zu finden. Eine bekannte Version davon ist **Gradient Descent**."
]
},
{
"cell_type": "markdown",
"id": "3c708f12",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "markdown",
"id": "f73093b8",
"metadata": {},
"source": [
"## Gradient Descent"
]
},
{
"cell_type": "markdown",
"id": "921a88b7",
"metadata": {},
"source": [
"\n",
"\n",
"(von https://ryanwingate.com/intro-to-machine-learning/deep-learning-with-pytorch/training-neural-networks-with-pytorch/)"
]
},
{
"cell_type": "markdown",
"id": "63527461",
"metadata": {},
"source": [
"Zuerst wollen wir uns einmal ansehen, woher der Begriff **Gradient Descent** eigentlich kommt."
]
},
{
"cell_type": "markdown",
"id": "9eb0066e",
"metadata": {},
"source": [
"**Gradient:** Eine mehrdimensionale Ableitung wird *Gradient* genannt. Wir verwenden dafür das Symbol $\\nabla$. Zum Beispiel hat die Funktion $f(x,y)=x^2+y^3+xy$ als Gradient den folgenden *Vektor*: $\\nabla f(x,y) = (\\frac{\\partial f}{\\partial x}, \\frac{\\partial f}{\\partial y}) = (2x+y,3y^2+x)$. Im Punkt $(1,1)$ ist somit der Gradient $\\nabla f(1,1) = (3,4)$. Er gibt also an, in welche Richtung die Funktion wie stark ansteigt (oder fällt bei einem negativen Vorzeichen). In unserem Fall steigt die Funktion am Punkt $(1,1)$ mit Steigung $3$ in Richtung $x$ und Steigung $4$ in Richtung $y$."
]
},
{
"cell_type": "markdown",
"id": "c5c80d03",
"metadata": {},
"source": [
"**Descent:** Englisches Wort für *Abstieg*."
]
},
{
"cell_type": "markdown",
"id": "8b185096",
"metadata": {},
"source": [
"Wir wollen also die besten Parameter für unser Modell finden, indem wir bei der Loss-Landscape immer in jene Richtung gehen, wo es am steilsten nach unten geht! Dabei wollen wir die Information vom Gradienten verwenden, also von der (mehrdimensionalen) Ableitung."
]
},
{
"cell_type": "markdown",
"id": "f3d604cf",
"metadata": {},
"source": [
"> **Übung:** Wie können wir diese Richtung finden?"
]
},
{
"cell_type": "markdown",
"id": "d449d2f4",
"metadata": {},
"source": [
"Der Gradient zeigt immer in jene Richtung, wo der Anstieg am größten ist. Somit geht es in die genau andere Richtung am steilsten nach unten!"
]
},
{
"cell_type": "markdown",
"id": "22002fbb",
"metadata": {},
"source": [
"Somit gehen wir bei dem Gradient Descent Algorithmus immer iterativ (also Schritt für Schritt) in die negative Richtung vom Gradienten an dem jeweiligen Punkt. Wie groß der Schritt in die jeweilige Richtung ist, wird über die sogenannte **Learning-Rate** $\\eta\\in \\mathbb R$ definiert. Sie ist in diesem Fall die Schrittweite und ein Hyperparameter, der vorher festgelegt werden muss. Wir formulieren nun die *Update-Rule*, also die Formel, mit der wir unsere Parameter $w$ vom neuronalen Netzwerk anpassen."
]
},
{
"cell_type": "markdown",
"id": "55b02e2a",
"metadata": {},
"source": [
"$$w_t = w_{t-1} - \\eta \\cdot \\nabla L(w_{t-1}).$$"
]
},
{
"cell_type": "markdown",
"id": "2cac2c81",
"metadata": {},
"source": [
"In Worten bedeutet das folgendes:\n",
"\n",
"Die Gewichte (Weights=Parameter) $w_t$ unseres Netzwerkes zum Zeitpunkt $t$ sind die bisherigen Gewichte $w_{t-1}$ minus dem Produkt aus Learning-Rate $\\eta$ und Gradienten (der Ableitung) von der Lossfunktion $L$ an der Stelle der bisherigen Parameter $w_{t-1}$. "
]
},
{
"cell_type": "markdown",
"id": "00e72fb7",
"metadata": {},
"source": [
"Vorstellen kann man sich das ganze folgendermaßen:\n",
"\n",
"* Man befindet sich irgendwo (zufällige Gewichte und somit Position am Anfang) in einem Gebirge (Loss-Landscape)\n",
"* Man möchte ins Tal (das *globale* Minimum finden)\n",
"* Es ist stark nebelig und man sieht nur, wie steil es an der aktuellen Position ist (Gradient bzw. negativer Gradient)\n",
"* Man bewegt sich einen kleinen Schritt (Learning Rate) in die Richtung des steilsten Abstiegs (Descent)\n",
"* Man wiederholt das ganze so lange, bis sich die Position nicht mehr wirklich ändert (Konvergenz)"
]
},
{
"cell_type": "markdown",
"id": "ee2bf385",
"metadata": {},
"source": [
"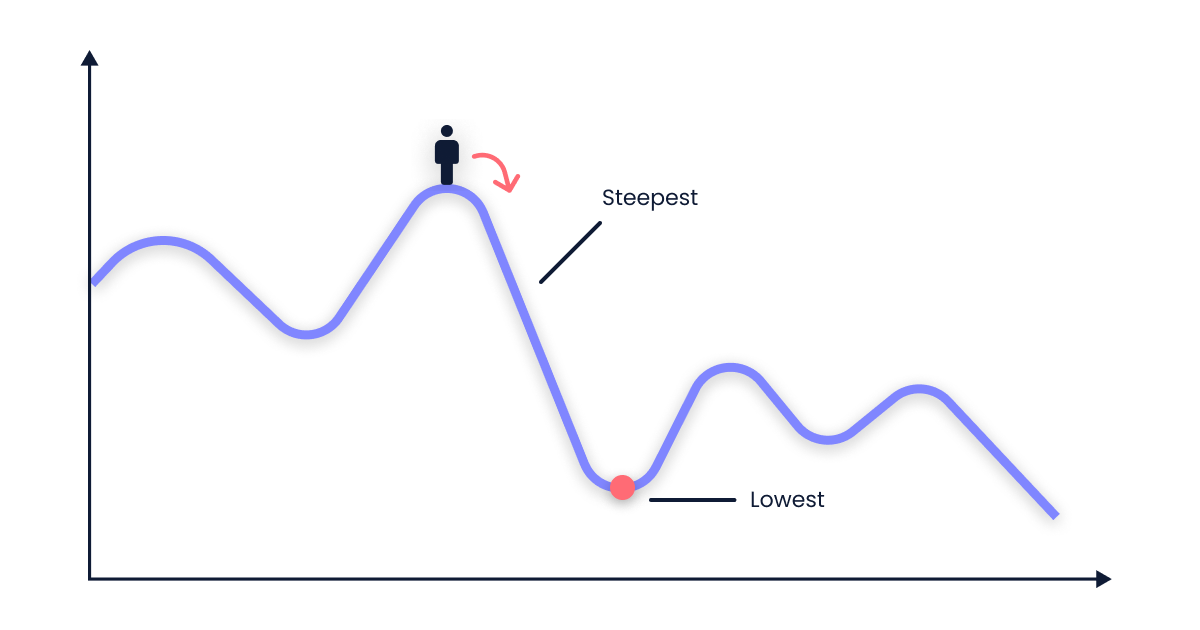\n",
"\n",
"(von https://krishparekh.hashnode.dev/gradient-descent)"
]
},
{
"cell_type": "markdown",
"id": "0bbb95b6",
"metadata": {},
"source": [
"Man kann sich das auch vorstellen, wie wenn man einen Ball die Loss Landscape herunterrollen lässt (ohne Trägheit etc.), wie das folgende Beispiel zeigt."
]
},
{
"cell_type": "markdown",
"id": "f054ceb0",
"metadata": {},
"source": [
"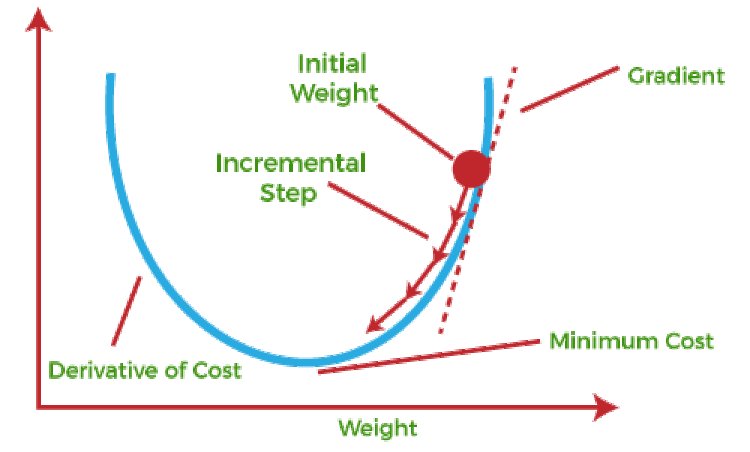\n",
"\n",
"(von https://datamites.com/blog/what-is-a-gradient-descent/?srsltid=AfmBOoozS1Fi9nBr4PlpiG-m1LHiooWr6KzNQ6IWiiJ6rrMqSuGxWfAz)"
]
},
{
"cell_type": "markdown",
"id": "6c98cee7",
"metadata": {},
"source": [
"> **Übung:** Warum ändert sich (bei passender Learning Rate) auf einmal die Position nicht mehr wirklich?"
]
},
{
"cell_type": "markdown",
"id": "b0e56a44",
"metadata": {},
"source": [
"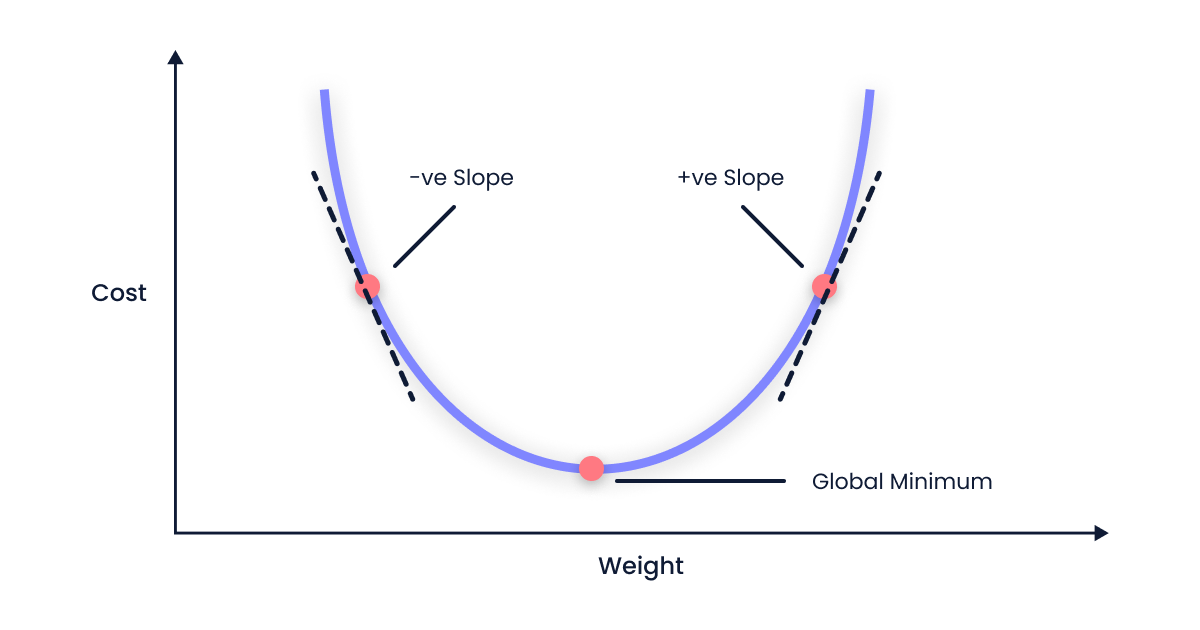\n",
"\n",
"(von https://krishparekh.hashnode.dev/gradient-descent)"
]
},
{
"cell_type": "markdown",
"id": "9fbf2595",
"metadata": {},
"source": [
"> **Übung:** Überlege, was bei so einer numerischen Methode schief gehen kann."
]
},
{
"cell_type": "markdown",
"id": "dcf834fa",
"metadata": {},
"source": [
"Es gibt 2 (bzw. 3) Dinge, die bei Optimieren mit Gradient Descent schief gehen können:\n",
"1. Wir landen in einem lokalen Minimum\n",
"2. Die Learning Rate passt nicht:\n",
" * Die Learning Rate ist zu klein\n",
" * Die Learning Rate ist zu groß"
]
},
{
"cell_type": "markdown",
"id": "ac08507a",
"metadata": {},
"source": [
"Erster Fall ist hier dargestellt."
]
},
{
"cell_type": "markdown",
"id": "baae3f41",
"metadata": {},
"source": [
"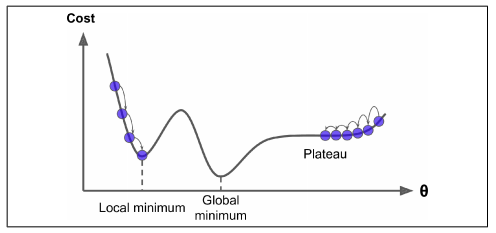\n",
"\n",
"(von https://nvsyashwanth.github.io/machinelearningmaster/understanding-gradient-descent/)"
]
},
{
"cell_type": "markdown",
"id": "89cafc90",
"metadata": {},
"source": [
"Es hängt also auch von der Startposition (wir starten mit zufälligen Gewichten) ab, wie gut das Netzwerk lernen kann. Wenn wir Pech haben, dann können wir keine gute Lösung finden."
]
},
{
"cell_type": "markdown",
"id": "5a084754",
"metadata": {},
"source": [
"Auch für die Learning Rates zeigen wir nun zwei mögliche (ungünstige) Fälle."
]
},
{
"cell_type": "markdown",
"id": "08e0dfeb",
"metadata": {},
"source": [
"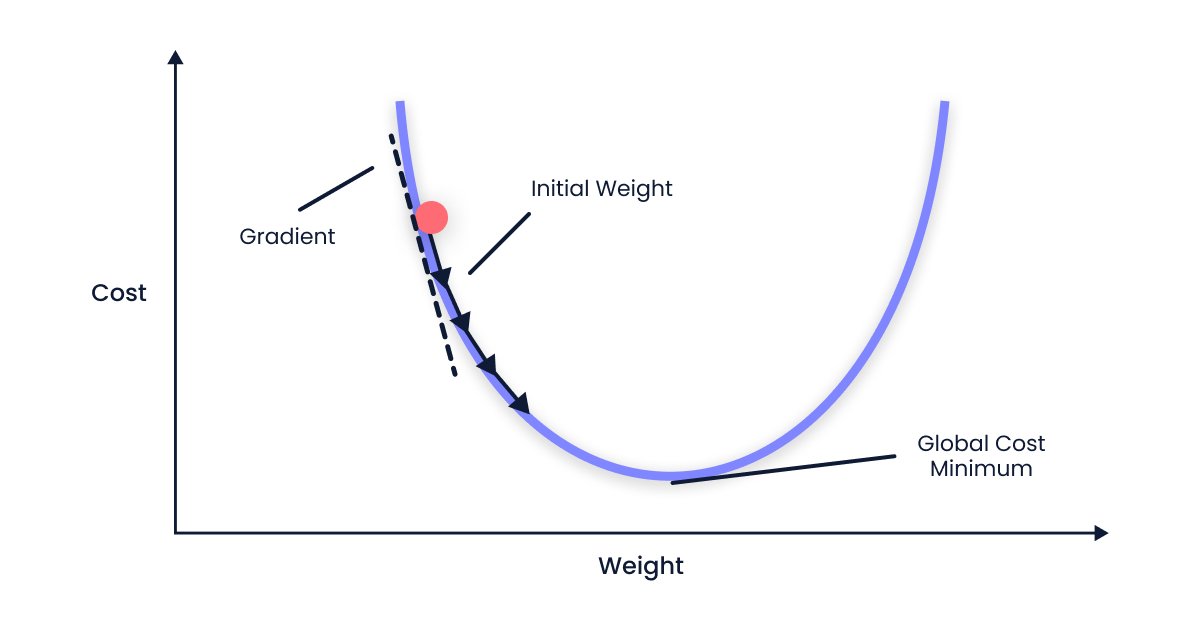\n",
"\n",
"(von https://krishparekh.hashnode.dev/gradient-descent)"
]
},
{
"cell_type": "markdown",
"id": "00347660",
"metadata": {},
"source": [
"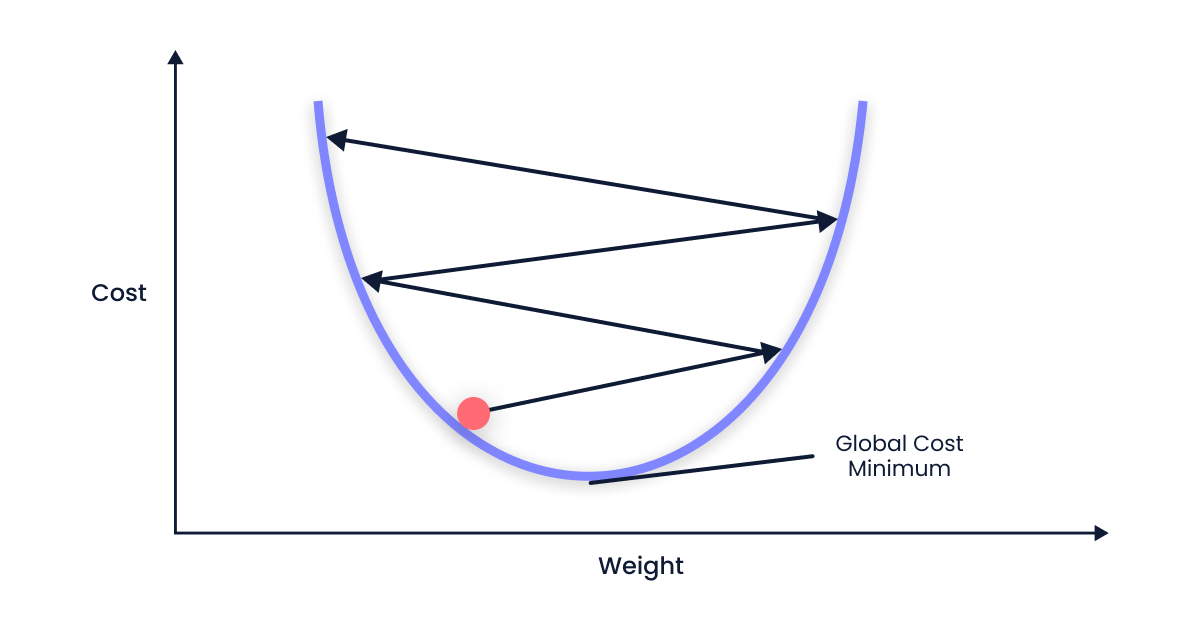\n",
"\n",
"(von https://krishparekh.hashnode.dev/gradient-descent)"
]
},
{
"cell_type": "markdown",
"id": "301b48b6",
"metadata": {},
"source": [
"**Wie können wir die eben erwähnten Probleme lösen?**"
]
},
{
"cell_type": "markdown",
"id": "701f7fa0",
"metadata": {},
"source": [
"Für eine zu kleine oder zu große Learning Rate ist die Lösung recht einfach: Wir müssen die Learning Rate verändern.\n",
"\n",
"Sprich sollten wir das Gefühl haben, die Performance vom Modell schwankt sehr stark, dann sollten wir die Learning Rate reduzieren. Genauso sollten wir, falls wir das Gefühl haben, dass unser Modell zu langsam lernt und der Loss nach wie vor jede Iteration weniger wird, die Learning Rate (etwas) erhöhen.\n",
"\n",
"Meistens liegt die Learning Rate im Hundertstel oder Tausendstel Bereich, sprich eine Standard Learning-Rate liegt oft im Bereich $0.001-0.01$."
]
},
{
"cell_type": "markdown",
"id": "869ee2a0",
"metadata": {},
"source": [
"**Hinweis:** Wir werden zu einem späteren Zeitpunkt sehen, wie wir den Lernprozess beobachten können (Spoiler: Wir lassen uns laufend aktuelle Werte vom Loss/Accuracy/etc. ausgeben) und somit beurteilen können, ob das Modell vernünftig lernt. Insbesondere werden wir uns das im Notebook bzgl. der *Trainingsmethode* ansehen."
]
},
{
"cell_type": "markdown",
"id": "a8199ada",
"metadata": {},
"source": [
"**Frage:** Was, wenn wir in einem lokalem Minimum landen?"
]
},
{
"cell_type": "markdown",
"id": "d6e67465",
"metadata": {},
"source": [
"So ein Fall tritt wahrscheinlich bei jedem der praktischen Machine Learning Problemen auf. Auch, wenn es natürlich erwünscht wäre, in einem globalen Minimum zu landen, müssen wir uns meistens mit einem lokalen Minimum zufrieden geben. Dies hat folgende Gründe:\n",
"* Wir können nicht wissen, ob wir in einem lokalen oder globalen Optimum sind\n",
"* Sofern die Performance (Loss oder andere Metriken) gut genug ist, sind wir zufrieden\n",
"* Es gibt ein paar theoretische Resultate, bei denen gezeigt wird, dass in vielen Fällen bei komplizierten Machine Learning Tasks alle (lokalen) Minima gleich gut sind."
]
},
{
"cell_type": "markdown",
"id": "f9425292",
"metadata": {},
"source": [
"Falls wir doch das Gefühl haben, dass unser Modell viel schlechter performt, als es sollte, so können wir:\n",
"* Hyperparameter ändern (Learning Rate, Modellarchitektur)\n",
"* Mehr Daten verwenden (nicht immer verfügbar)\n",
"* Die Gewichte anders zufällig initialisieren (unüblich, nur \"Experten\" verändern diese Initialisierung, bringt nur in Spezialfällen was)\n",
"* Einen anderen Optimierungsalgorithmus, sprich einen anderen Optimizer verwenden."
]
},
{
"cell_type": "markdown",
"id": "ba79b08f",
"metadata": {},
"source": [
"**Hinweis:** Als Optimierer wird jener Algorithmus bezeichnet, der verwendet wird um zu lernen. In unserem Fall zBsp. (eine Variante von) Gradient Descent. Eine sehr bekannte Variante davon ist **Stochastic Gradient Descent** (SGD), welchen wir uns nun genauer ansehen wollen."
]
},
{
"cell_type": "markdown",
"id": "42c03208",
"metadata": {},
"source": [
"## Stochastic Gradient Descent"
]
},
{
"cell_type": "markdown",
"id": "0b4380eb",
"metadata": {},
"source": [
"Der erste Optimizer den wir betrachten wollen ist der sogenannte *Stochastic Gradient Descent* (**SGD**) Algorithmus. "
]
},
{
"cell_type": "markdown",
"id": "f249d352",
"metadata": {},
"source": [
"Er ist quasi der \"Standard\" Algorithmus in PyTorch für die Optimierung, und adaptiert den bisher besprochenen (Vanilla) Gradient Descent Algorithmus nur leicht."
]
},
{
"cell_type": "markdown",
"id": "e2147ca5",
"metadata": {},
"source": [
"Sehen wir uns zuerst ein Bild an, welches den Stochastic Gradient Descent mit dem (Vanilla) Gradient Descent vergleicht."
]
},
{
"cell_type": "markdown",
"id": "539515e6",
"metadata": {},
"source": [
"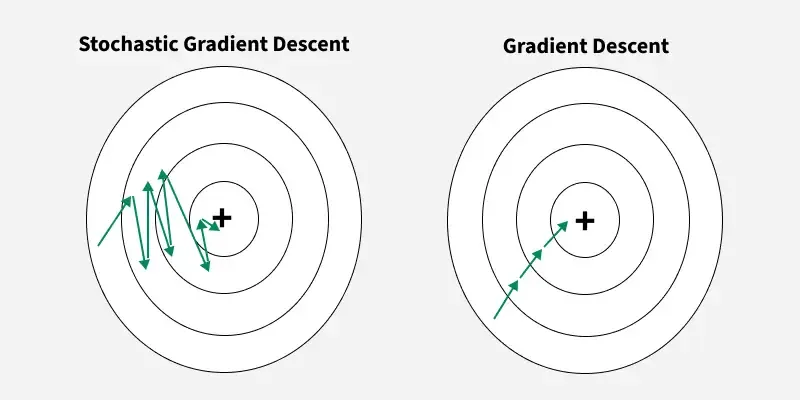\n",
"\n",
"(von https://www.geeksforgeeks.org/machine-learning/ml-stochastic-gradient-descent-sgd/)"
]
},
{
"cell_type": "markdown",
"id": "1c1969da",
"metadata": {},
"source": [
"Dieses Bild sieht jetzt vermutlich unintuitiv aus, weil die einzelnen Schritte des (Vanilla) Gradient Descent Algorithmus ja wesentlich besser aussehen. Diese Sichtweise ist teilweise richtig. Sehen wir uns mal die Details vom Stochastic Gradient Descent Algorithmus an."
]
},
{
"cell_type": "markdown",
"id": "1254a0bd",
"metadata": {},
"source": [
"Beim *SGD* ist die Update Rule leicht angepasst:\n",
"$$w_t = w_{t-1} - \\eta \\cdot \\nabla L_I(w_{t-1}).$$"
]
},
{
"cell_type": "markdown",
"id": "3f504b8a",
"metadata": {},
"source": [
"Der einzige Unterschied ist also, dass wir jetzt die Ableitung (den Gradient) von $L_I$ nehmen. Dabei bezeichnen wir mit $L_I$ die Loss-Funktion auf eine Teilmenge der Daten.\n",
"\n",
"Sprich einfach gesagt macht Stochastic Gradient Descent nichts anderes als Gradient Descent, nur wird der Fehler und somit auch die Ableitung nur für ein paar wenige Datenpaare $(\\hat y, y)$ berechnet anstatt für alle. Dabei werden die Datenpaare zufällig ausgewählt (stochastisch)."
]
},
{
"cell_type": "markdown",
"id": "b905eb8f",
"metadata": {},
"source": [
"**Vorteile von SGD:**\n",
"* Schneller, weil die Ableitung für weniger Punkte berechnet werden muss\n",
"* Aufgrund von zufälliger Wahl der Datenpaare wird dem Optimierungsprozess etwas Stochastik (\"Zufall\") hinzugefügt, dadurch besteht die Chance, aus lokalen Minima auszubrechen\n",
"* Garantie, dass wir in Erwartung (im Mittel) das gleiche machen wie der (Vanilla) Gradient Descent Algorithmus (Sprich der Algorithmus macht quasi im Mittel Sinn)."
]
},
{
"cell_type": "markdown",
"id": "05a133e0",
"metadata": {},
"source": [
"**Nachteile von SGD:**\n",
"* Stochastik führt zu \"instabilerem\" Training (der Effekt ist aber nicht so drastisch, wie im obigen Bild dargestellt.)\n",
"* Schlechte Nachvollziehbarkeit/Reproduzierbarkeit"
]
},
{
"cell_type": "markdown",
"id": "effb0d45",
"metadata": {},
"source": [
"**Hinweis:** Den (Vanilla) Gradient Descent gibt es in PyTorch eigentlich nicht direkt. Es wird eigentlich immer *SGD* verwendeten, falls von Gradient Descent gesprochen wird."
]
},
{
"cell_type": "markdown",
"id": "90b29550",
"metadata": {},
"source": [
"**Wichtig:** Es gibt auch andere Optimierungsverfahren, bei denen die Formeln für die Updates aufwendiger sind, jedoch in manchen Fällen bessere Konvergenzverhalten liefern. Ein Beispiel dafür ist zum Beispiel **Adam** oder **Adagrad**, diese können genauso verwendet werden und funktionieren für viele Probleme besser (bzw. meistens nicht schlechter). Wir werden diese aber nicht in der Theorie behandeln."
]
},
{
"cell_type": "markdown",
"id": "f929e1df",
"metadata": {},
"source": [
"\n",
"\n",
"(von https://x.com/drob/status/1425468713017425923)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Optimizer in PyTorch"
]
},
{
"cell_type": "markdown",
"id": "4bbe53ce",
"metadata": {},
"source": [
"Befassen wir uns nun damit, wie wir in Python (PyTorch) die Optimizer verwenden können und was sie bewirken."
]
},
{
"cell_type": "markdown",
"id": "5aaf4494",
"metadata": {},
"source": [
"Annahme, wir wollen die Funktion $f(w)=(w-3)^2$ minimieren. Wir sehen zwar relativ schnell, dass diese Funktion bei $x=3$ ihr Minimum erreicht, jedoch wollen wir das nun auch mit dem Gradient Descent Algorithmus zeigen."
]
},
{
"cell_type": "markdown",
"id": "26c3f80b",
"metadata": {},
"source": [
"**Hinweis:** Obiges Beispiel könnte man sich vorstellen, wie wenn wir die Funktion $f(x)=x$ haben mit Loss Funktion $g(x)=x^2$, sprich dem Mean Squarred Error. Das Label wär nun 3."
]
},
{
"cell_type": "markdown",
"id": "f5bcd79d",
"metadata": {},
"source": [
"> **Übung:** Berechne die Werte von $w$ für die ersten 3 Iterationen mit (Vanilla) Gradient Descent, wobei als Startwert $w=0$ verwendet werden soll und als Learning Rate $\\eta = 0.25$.\n",
"\n",
"Als Hilfestellung wird hier die Update-Rule nochmal dargestellt:\n",
"$$w_t = w_{t-1} - \\eta \\cdot \\nabla L(w_{t-1}).$$\n",
"Anders geschrieben (\"Programmierschreibweise\") heißt das\n",
"$$w \\mathrel{-}= \\eta \\cdot \\nabla L(w).$$\n",
"In unserem Fall (weil 1d) dann:\n",
"$$w \\mathrel{-}= \\eta \\cdot f'(w).$$"
]
},
{
"cell_type": "markdown",
"id": "8b97bf3c",
"metadata": {},
"source": [
"**Dieses Beispiel in PyTorch:**"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "250bec9a",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Schritt 0: x = [0.0], f(x) = 9.0000\n",
"Schritt 1: x = [1.5], f(x) = 9.0000\n",
"Schritt 2: x = [2.25], f(x) = 2.2500\n",
"Schritt 3: x = [2.625], f(x) = 0.5625\n",
"Schritt 4: x = [2.8125], f(x) = 0.1406\n",
"Schritt 5: x = [2.90625], f(x) = 0.0352\n",
"Schritt 6: x = [2.953125], f(x) = 0.0088\n",
"Schritt 7: x = [2.9765625], f(x) = 0.0022\n",
"Schritt 8: x = [2.98828125], f(x) = 0.0005\n",
"Schritt 9: x = [2.994140625], f(x) = 0.0001\n",
"Schritt 10: x = [2.9970703125], f(x) = 0.0000\n"
]
}
],
"source": [
"import torch\n",
"\n",
"learning_rate = 0.25\n",
"\n",
"# Parameter als Tensor mit Gradienten\n",
"x = torch.tensor([0.0], requires_grad=True)\n",
"optimizer = torch.optim.SGD([x], lr=learning_rate)\n",
"\n",
"def f(x):\n",
" return (x - 3)**2\n",
"\n",
"loss = f(x)\n",
"print(f\"Schritt 0: x = {x.tolist()}, f(x) = {loss.item():.4f}\")\n",
"for i in range(10):\n",
" optimizer.zero_grad() # Gradienten zurücksetzen\n",
" loss = f(x)\n",
" loss.backward() # Gradient berechnen\n",
" optimizer.step() # Update-Schritt\n",
" print(f\"Schritt {i+1}: x = {x.tolist()}, f(x) = {loss.item():.4f}\")"
]
},
{
"cell_type": "markdown",
"id": "85e80b0d",
"metadata": {},
"source": [
"Hierbei sind folgende Punkte sehr wichtig in unserer Methode oben:\n",
"\n",
"* `x = torch.tensor([0.0], requires_grad=True)` $x$ muss ein Tensor sein, bei dem der Gradient gespeichert wird. Startwert ist in unserem Fall $0.0$.\n",
"* `optimizer = torch.optim.SGD([x], lr=learning_rate)` Der Optimizer muss die Parameter des Modells kennen (in unserem Fall ist unser Modell nur $x$)\n",
"* `optimizer.zero_grad()` Am Anfang jeder Iteration muss der Gradient wieder aus dem Optimizer gelöscht werden (wir wollen ja wieder einen neuen Gradienten berechnen)\n",
"* `loss = f(x)` Diese Zeile würde bei einem neuronalen Netz dann die Prediction mit dem True Label vergleichen\n",
"* `loss.backward()` Berechnet die Gradienten bzgl. **aller** Parameter, die vorher dem Optimizer übergeben wurden\n",
"* `optimizer.step()` Führt das Update $w_t = w_{t-1} - \\eta \\cdot \\nabla L(w_{t-1})$ durch"
]
},
{
"cell_type": "markdown",
"id": "137947aa",
"metadata": {},
"source": [
"> **Übung:** Verändere den obigen Code so, dass wir für die drei vorigen Aufgaben vom Beginn das (bzw. ein) Minimum finden. Ändere dazu die Dimension (und ggf. den Startwert) von $x$.\n",
"\n",
"Die verwendeten Funktionen waren:"
]
},
{
"cell_type": "markdown",
"id": "f67a2dd4",
"metadata": {},
"source": [
"$$L(w_1, w_2)=(4w_1+7w_2-20)^2$$\n",
"$$L(w_1, w_2, w_3)=\\max (0, 2w_1+3w_2-4w_3)^2$$\n",
"$$L(w_1)=\\lvert w_1 - e^{-w_1} \\rvert$$"
]
},
{
"cell_type": "markdown",
"id": "aa4adea8",
"metadata": {},
"source": [
"> **Übung:** Probiere auch die Optimizer *Adam* und *Adagrad* aus, indem du sie mit den Befehlen `from torch.optim import Adagrad, Adam` importierst und im Anschluss statt `SGD` verwendest."
]
},
{
"cell_type": "markdown",
"id": "069dc97d",
"metadata": {},
"source": [
"## Loss Funktionen in PyTorch"
]
},
{
"cell_type": "markdown",
"id": "605742b2",
"metadata": {},
"source": [
"Last but not least wollen wir uns noch die Loss-Funktionen in PyTorch ansehen."
]
},
{
"cell_type": "markdown",
"id": "0e909c5e",
"metadata": {},
"source": [
"Prinzipiell ist das Auswählen einer Loss-Funktion eine sehr kritische Sache, da wir im Laufe des Trainings versuchen, den Loss des Neuronalen Netzwerks zu reduzieren, idealerweise das (globale) Minimum davon zu finden. Es gibt jedoch für die Standard Probleme gängige Loss-Funktionen, die in vielen Fällen tadellos funktionieren. \n",
"\n",
"Diese beiden sind die bereits bekannten Funktionen:\n",
"* MSE (Mean Squared Error) für Regression\n",
"* (Binary) Cross-Entropy Loss für Klassifikation"
]
},
{
"cell_type": "markdown",
"id": "80220b45",
"metadata": {},
"source": [
"Verwendet kann dies folgendermaßen werden."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d070bf0a",
"metadata": {},
"outputs": [],
"source": [
"from torch.nn import CrossEntropyLoss, MSELoss"
]
},
{
"cell_type": "markdown",
"id": "3d1019f4",
"metadata": {},
"source": [
"Dies sind jetzt noch Klassen, welche noch instanziert werden müssen."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b5661912",
"metadata": {},
"outputs": [],
"source": [
"loss_fn = MSELoss()\n",
"loss_fn = CrossEntropyLoss()"
]
},
{
"cell_type": "markdown",
"id": "b3cd8487",
"metadata": {},
"source": [
"Beides sind Funktionen, welche sich dann aufrufen lassen mit `loss_fn(input, target)`."
]
},
{
"cell_type": "markdown",
"id": "1c4ffa00",
"metadata": {},
"source": [
"Auch, wenn der Output gleich ist wie oben beschrieben gibt es ein paar implementierungsspezifische Details, auf die man bei der Verwendung achten muss. Ein paar Dinge werden wir hier aufzählen. Allgemein findet man natürlich die Infos in der Dokumentation. So zum Beispiel auch für den [Cross-Entropy-Loss](https://docs.pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html)."
]
},
{
"cell_type": "markdown",
"id": "5c9990d9",
"metadata": {},
"source": [
"Besonderheiten in der Implementierung:\n",
"* Wir erwarten uns beim Output Layer für eine Klassifikation normalerweise einen \"Wahrscheinlichkeitsvektor\", sprich die Summe muss 1 ergeben. Dies erreichen wir mit der Softmax Funktion am Schluss vom Netzwerk. In der Implementierung von PyTorch werden aber die Werte **vor der Softmax** Funktion erwartet\n",
"* Wir haben bisher gelernt, dass wir für die Klassifikation **One-Hot**-Vektoren für die Labels brauchen. Das stimmt in der Theorie, jedoch für die Implementierung reicht ein Integer Label aus."
]
},
{
"cell_type": "markdown",
"id": "c9162a3e",
"metadata": {},
"source": [
"> **Übung:** Warum reicht ein Integer Label aus, um den Loss zu berechnen? (Sprich warum kann sich PyTorch das Transformieren zu einem One-Hot Vektor sparen?)"
]
},
{
"cell_type": "markdown",
"id": "5be53daa",
"metadata": {},
"source": [
"**Hinweis:** (Nicht recht relevant für Test): Für eine Multiclass Klassifikation (wird bei uns nicht behandelt) reicht ein Index natürlich nicht mehr aus."
]
},
{
"cell_type": "markdown",
"id": "6dc09db0",
"metadata": {},
"source": [
"**Wichtig:** Solche Implementierungsdetails sollen beim Implementieren bekannt sein (oder beim Auftreten der Probleme zumindest nicht überraschen), jedoch ist es wichtiger, dass die zu Grunde liegende Theorie verstanden wird! "
]
},
{
"cell_type": "markdown",
"id": "1150531f",
"metadata": {},
"source": [
"## Vanishing and Exploding Gradient"
]
},
{
"cell_type": "markdown",
"id": "abd88832",
"metadata": {},
"source": [
"Ok, nachdem wir jetzt wissen, wie ein Neuronales Netzwerk lernt, stellt man sich vielleicht die Frage, warum man nicht einfach ein riesiges (tiefes) Netzwerk verwendet. Immerhin kann man dann mit Gradient Descent oder verwandte/ähnliche Optimierer die (hoffentlich) beste Lösung finden und man hat eine gute Performance."
]
},
{
"cell_type": "markdown",
"id": "1a2f407d",
"metadata": {},
"source": [
"Die Idee ist zwar prinzipiell nicht falsch, jedoch funktioniert das in der Praxis nicht. Grund dafür ist der sogenannte **Vanishing Gradient** Effekt. "
]
},
{
"cell_type": "markdown",
"id": "e0ab7dae",
"metadata": {},
"source": [
"### Vanishing Gradient"
]
},
{
"cell_type": "markdown",
"id": "3bca56ea",
"metadata": {},
"source": [
"(Erstmals formalisiert/festgestellt von Prof. Sepp Hochreiter 1991)."
]
},
{
"cell_type": "markdown",
"id": "361a82e2",
"metadata": {},
"source": [
"Nachdem beim Gradient Descent die Ableitungen bezüglich der Gewichte berechnet werden, kommt natürlich auch die Kettenregel ins Spiel. Das wird bei zu tiefen Modellen oft ein Problem, da zum Beispiel\n",
"\n",
"$$\\frac{\\partial L}{\\partial w_1} = \\frac{\\partial L}{\\partial a_n}\\underbrace{\\frac{\\partial a_n}{\\partial z_n}}_{=f'(a_n)} \\frac{\\partial z_n}{\\partial a_{n-1}}\\cdots \\frac{\\partial z_3}{\\partial a_2}\\underbrace{\\frac{\\partial a_2}{\\partial z_2}}_{=f'(a_2)}\\frac{\\partial z_2}{\\partial a_1}\\underbrace{\\frac{\\partial a_1}{\\partial z_1}}_{=f'(a_1)}\\frac{\\partial z_1}{\\partial w_1}.$$"
]
},
{
"cell_type": "markdown",
"id": "219b46bc",
"metadata": {},
"source": [
"> **Übung:** Wie nennt man obige Regel beim Ableiten?"
]
},
{
"cell_type": "markdown",
"id": "a2c10f0a",
"metadata": {},
"source": [
"Hier stellt $f$ die Aktivierungsfunktion, somit $f'$ die Ableitung davon dar."
]
},
{
"cell_type": "markdown",
"id": "d0b0edd6",
"metadata": {},
"source": [
"Warum ist das ein Problem?"
]
},
{
"cell_type": "markdown",
"id": "872f81c3",
"metadata": {},
"source": [
"Wenn wir uns die Ableitung von der Sigmoid Funktion $\\sigma(x) = (1+e^{-x})^{-1}$ ansehen, dann erhalten wir\n",
"$$\\sigma'(x) = \\sigma(x) \\cdot (1-\\sigma(x)).$$\n",
"\n",
"Diese Funktion hat als Maximalwert $0.25$. Mit der Kettenregel wird dieser Wert aber je nach Tiefe oft multipliziert."
]
},
{
"cell_type": "markdown",
"id": "a66201e6",
"metadata": {},
"source": [
"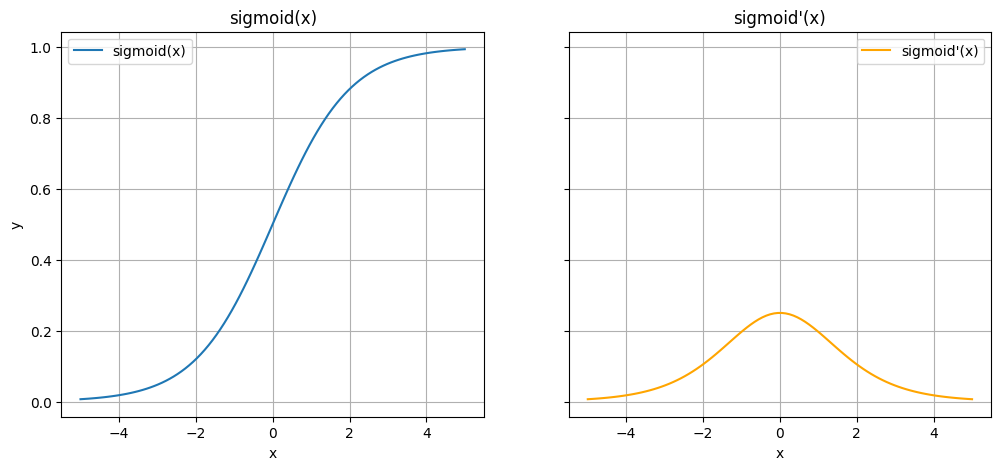\n",
"\n",
"(eigene Abbildung)"
]
},
{
"cell_type": "markdown",
"id": "98ce7ce3",
"metadata": {},
"source": [
"Das bedeutet, wenn wir die Sigmoid Funktion als Aktivierungsfunktion verwenden und ein sehr tiefes Netzwerk verwenden, dann wird die Ableitung bezüglich der Gewichte am Anfang sehr klein (sie verschwindet - it vanishes)."
]
},
{
"cell_type": "markdown",
"id": "0ecd3b3c",
"metadata": {},
"source": [
"Somit werden **extrem tiefe Modelle nicht mehr lernbar**, wenn die Sigmoid (oder vergleichbare) Aktivierungsfunktion verwendet wird. "
]
},
{
"cell_type": "markdown",
"id": "50dd44dd",
"metadata": {},
"source": [
"**Hinweis:** Die Aktivierungsfunktionen müssen natürlich nicht gleich sein bei jeder Schicht, aber mit jedem zusätzlichen Layer wird das Netzwerk tiefer und somit mit der Kettenregel ein weiterer Term (bzw. 2 weitere Terme) dazu multipliziert."
]
},
{
"cell_type": "markdown",
"id": "d2b16ad3",
"metadata": {},
"source": [
"### Exploding Gradient"
]
},
{
"cell_type": "markdown",
"id": "28d6b444",
"metadata": {},
"source": [
"Das gleiche Problem kann passieren, wenn wir Aktivierungsfunktionen verwenden, bei denen die Ableitung größer als 1 ist. In solchen Fällen wird der Gradient sehr groß (er explodiert). Auch solche Netzwerke sind nicht lernbar."
]
},
{
"cell_type": "markdown",
"id": "d0cd639f",
"metadata": {},
"source": [
"> **Übung:** Warum sind Netzwerke, welche vom *Exploding-Gradient* betroffen sind, nicht lernbar?"
]
},
{
"cell_type": "markdown",
"id": "752db18f",
"metadata": {},
"source": [
"### Gradient $\\approx$ 1"
]
},
{
"cell_type": "markdown",
"id": "9aec786d",
"metadata": {},
"source": [
"Ideal ist natürlich eine Aktivierungsfunktion mit Werte der Ableitung in der Größenordnung 1. Solche Netzwerke können viel tiefer gemacht werden und leiden somit nicht unter den beiden oben genannten Problemen.\n",
"\n",
"Ein sehr guter Kandidat: $\\mathrm{ReLU}(x)$. Jedoch ist hier in vielen Fällen die Ableitung $0$."
]
},
{
"cell_type": "markdown",
"id": "329cc9ca",
"metadata": {},
"source": [
"**Hinweis:** In der Theorie kann natürlich ein Netzwerk bei genügend Iterationen/Epochen trainiert werden. Hier können die Gradienten dann zwar sehr sehr sehr klein werden, jedoch sind sie nicht $0$. In der Praxis sind die sehr kleinen Gradienten ein Problem, weil sie erstens den Trainingsprozess verlangsamen und andererseits ab einer gewissen Größe der Computer sie nicht mehr von der $0$ unterscheiden kann!"
]
},
{
"cell_type": "markdown",
"id": "c1854d33",
"metadata": {},
"source": [
"\n",
"\n",
"(Eigene Grafik mit imgflip.com)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "dsai",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.13.5"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
 \n",
"
\n",
"